Spark
RDD
Resilient Distributed Datasets (RDDs)
Spark 围绕着弹性分布式数据集(RDD)的概念展开,它是一个可以并行操作,并且容错的元素集合。有两种方法可以创建 RDD:
- 并行化在驱动程序中现有的集合(本地集合)
- 外部存储系统中的数据集(HDFS、HBase、任何 Hadoop 输入格式的数据源)
两种共享变量(Shared Variables)
- 广播变量(Broadcast Variables)
- 累加器(Accumulators)
SQL、DataFrammes、Datasets
Spark SQL 是 Spark 的一个模块,为了 与基本的 Spark RDD API 不同的是 Spark SQL 接口提供了关于数据结构的信息,这些信息优化了数据处理。
Spark 1.6 新增了 Dataset,Dataset 可以从 JVM 对象构造,然后经过 transform 函数进行操作。DataFrame 是一个特殊的 Dataset,是一个组织成命名列的 Dataset。
换一种表达
Structured Streaming
结构化流处理是一个构建在的可扩展和容错的流处理引擎。您可以像表示静态数据上的批处理计算一样表示流式计算。
// Create DataFrame representing the stream of input lines from connection to localhost:9999
Dataset<Row> lines = spark
.readStream()
.format("socket")
.option("host", "localhost")
.option("port", 9999)
.load();
// Split the lines into words
Dataset<String> words = lines
.as(Encoders.STRING())
.flatMap((FlatMapFunction<String, String>) x -> Arrays.asList(x.split(" ")).iterator(), Encoders.STRING());
// Generate running word count
Dataset<Row> wordCounts = words.groupBy("value").count();
// Start running the query that prints the running counts to the console
StreamingQuery query = wordCounts.writeStream()
.outputMode("complete")
.format("console")
.start();
query.awaitTermination();
Spark Streaming (DStreams)
提示
Spark Streaming 是上一代流式计算引擎,Spark 不再更新它。
新的、更容易的流式引擎叫做结构化流(Structed Streaming)
Spark Streaming 是 Spark Core 的一个扩展,是一个高吞吐、容错的流式处理引擎。数据源可以来自 Kafka、Kinesis、TCP sockets 等。
// Create a local StreamingContext with two working thread and batch interval of 1 second
SparkConf conf = new SparkConf().setMaster("local[2]").setAppName("NetworkWordCount");
JavaStreamingContext jssc = new JavaStreamingContext(conf, Durations.seconds(1));
// Create a DStream that will connect to hostname:port, like localhost:9999
JavaReceiverInputDStream<String> lines = jssc.socketTextStream("localhost", 9999);
// Split each line into words
JavaDStream<String> words = lines.flatMap(x -> Arrays.asList(x.split(" ")).iterator());
// do some transform
jssc.start(); // Start the computation
jssc.awaitTermination(); // Wait for the computation to terminate
MLib (Machine Learning)
GraphX (Graph Processing)
SparkR
PySpark
Spark 常见问题
1)Spark数据倾斜的解决方案
(1)增加并行度使得数据多的partition数据分散
(2)自定义partitioner让数据更均匀的分散在各个task上计算
(3)大小RDD join时与其在map端join不如把小RDD作为广播变量,使得join操作发生在reduce端
(4)给数据量特别大的key上加随机前缀,那么这个倾斜数据会分散均匀,然后再把少量数据的key和随机前缀集合做笛卡尔乘积,然后就可以让这两份数据join
(5)当上面说的量大的key特别多时可以让全部key都加随机前缀,这样操作简单,缺点就是把数据扩大了N倍,这个N就是随机前缀集合大小
2)Shuffle是什么?
当RDD之间的关系是宽依赖时会发生shuffle,shuffle是根据某个规则将数据打乱迁移的过程。
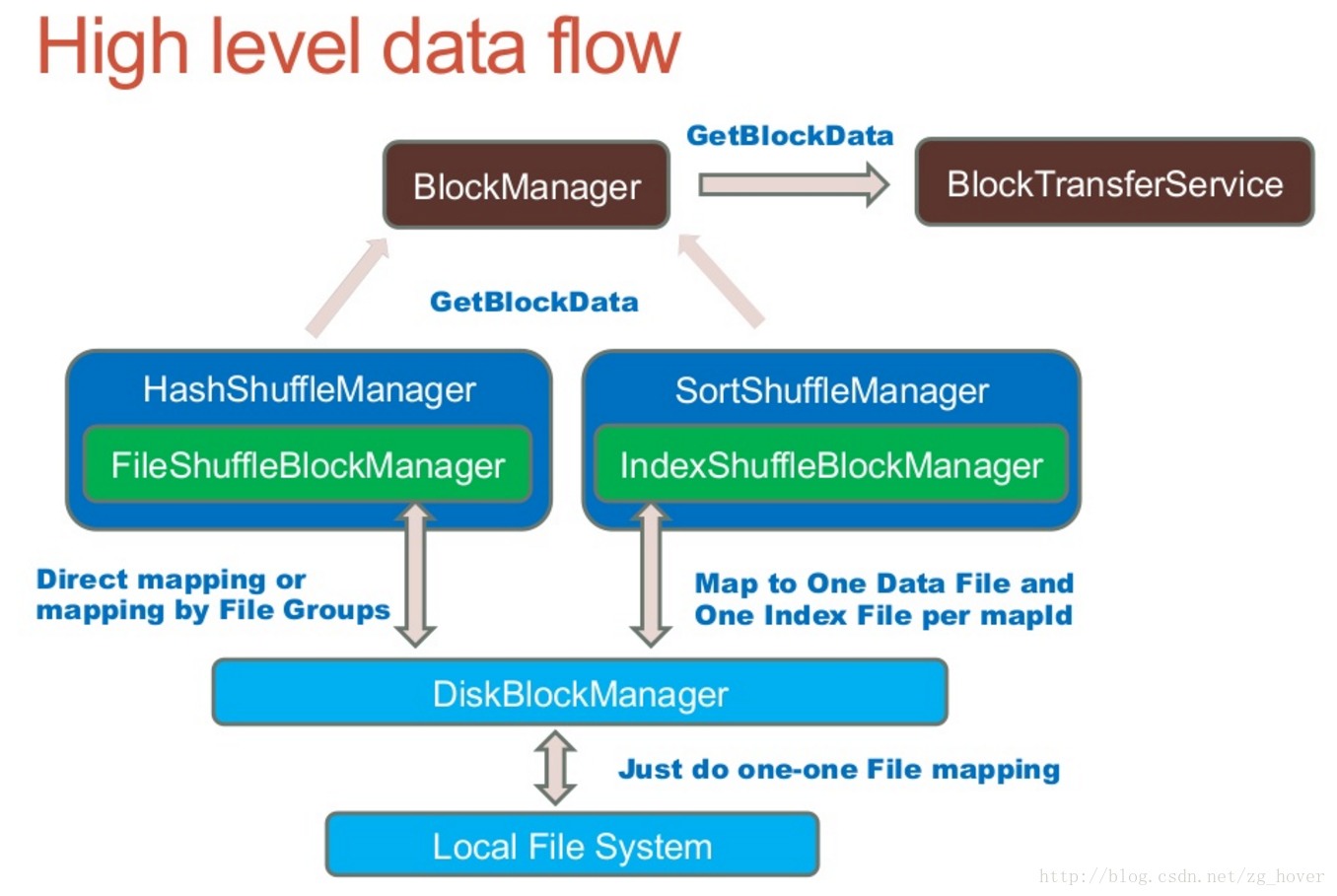
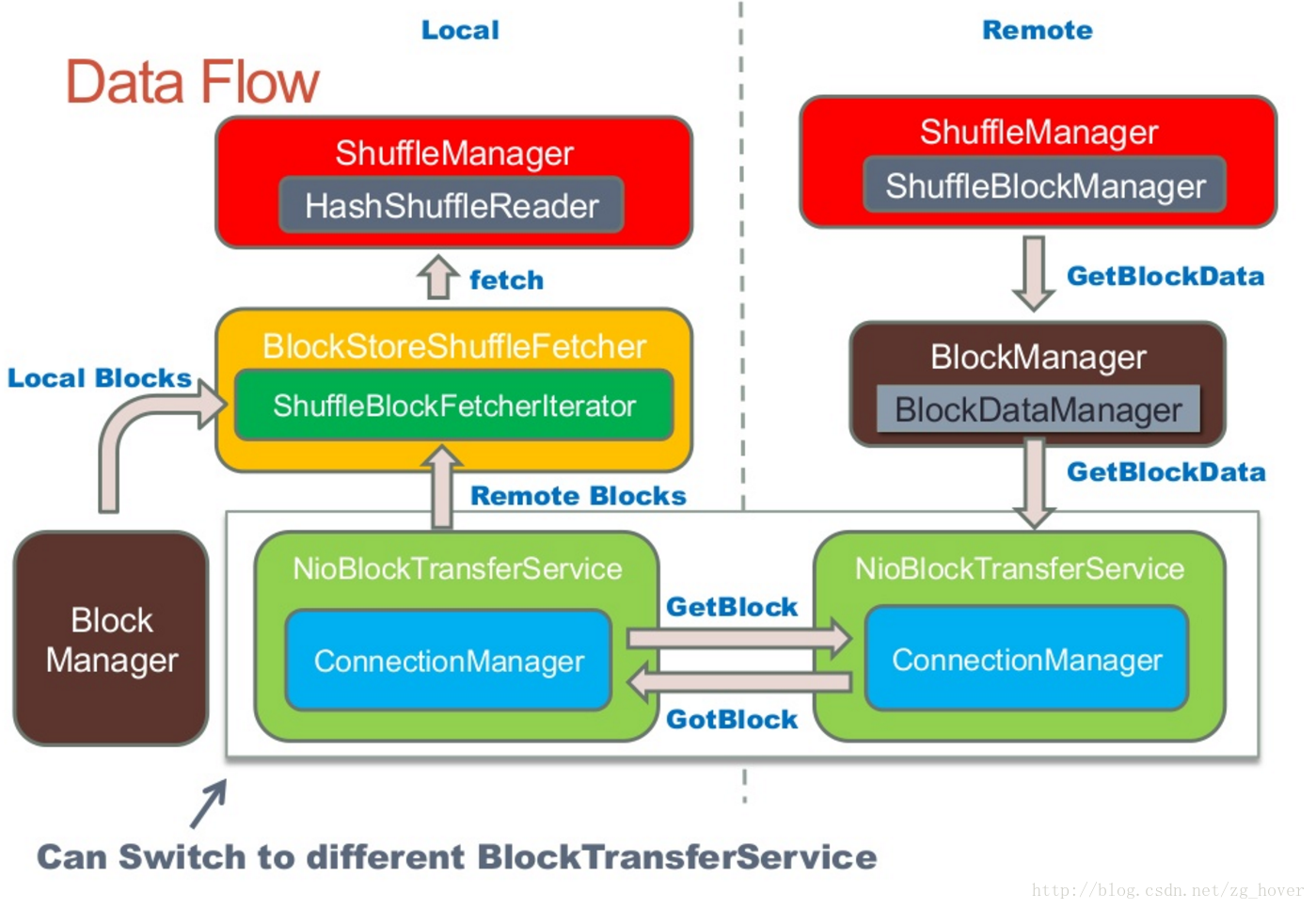
Spark Shuffle说到shuffle不得不先提及一下分区的概念,分区是spark并行度中最小的粒度,也就是有多少分区就最多有多少条线程同时处理它,对应到spark 上就是有多少个task同时处理。那么当一个RDD根据partitioner(spark默认是HashPartitioner)重分区时,首先每个task利用各自的partitioner开始分区, 分区完成的数据写入磁盘,这个时候所有节点本地都有指定数量的分区数据(这个是优化后的HashShuffleManager),然后executor上报分区信息给driver,根据driver 上面的分区信息下一个stage的计算时,计算的task会把数据fetch下来。这个过程就是shuffle。
【总结一下】shuffle过程涉及新分区计算、数据传输网络I/O、数据压缩、磁盘I/O所以代价很大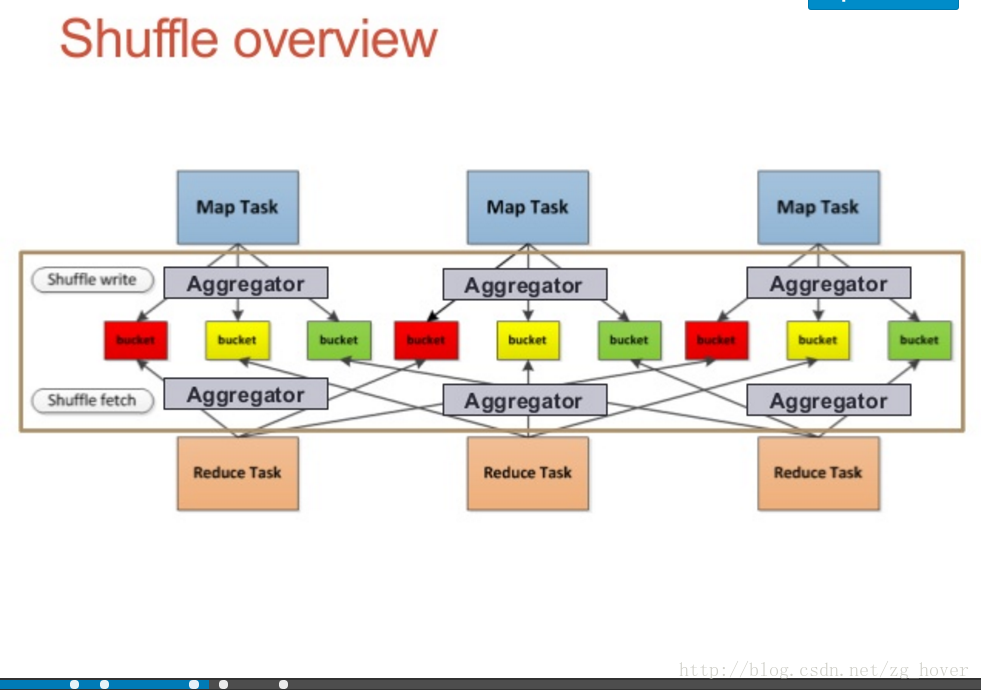
3)Spark有哪些聚合类的算子,我们应该尽量避免什么类型的算子?
涉及到shuffle的一些算子比如:repartition、reduceByKey、groupByKey、join、distinct等因为shuffle的代价太大了,应该尽可能多选用map类的算子
4)Spark各个组件、它的集群发布模式有哪些(集群架构)
Spark在独立集群下有master、work两类物理节点,除了standalone集群当然还有yarn、mesos、kubernetes集群(这些集群就是对应submit时--master参数的选择)
无论哪种集群都有driver和executor两类进程。
无论哪种集群都有client和cluster两种发布模式。
client模式都是driver是在client运行,然后master和driver通信。cluster模式都是driver在集群中的一个worker上运行,然后client断开退出。以下举两个集群例子:
spark standalone集群中有多个master节点和多个work节点。master节点常驻master进程负责管理work节点,并且我们是从master节点上提交应用。 work节点常驻work进程与master进程通信并且管理executor进程。
spark on yarn集群中那就对应有AM和其他container。client模式下AM只负责申请资源和client driver通信,其他container负责执行executor; cluster模式下AM负责driver启动、管理资源调度等等,其他container还是负责执行executor。
5)Spark on yarn , client 和 cluster模式的工作流程是啥,有啥区别?
其实每种集群的client和cluster发布模式都大同小异,大体上都是:client模式driver程序运行在client端,client端保持和work进程的通信;cluster模式 driver运行在集群的某一个节点上,client断开连接退出。
Spark on yarn也不例外,client模式:
- 首先在client端启动driver进程
- Driver进程执行我们提交的应用程序,构造SparkConf、SparkContext。SparkContext在初始化的时候主要就是构造DAGScheduler和TaskScheduler。
TaskScheduler会通过一个后台进程去连接master(这时的master是yarn集群分配出来的AM)向master注册Application。
master收到注册信息请求后,利用自己的调度算法(各个集群yarn、mesos、kubernetes都不一样)在Spark集群的worker上为这个程序启动executor进程。
Executor启动后会反向注册到TaskScheduler上。当所有的executor都反向注册完成之后,Driver就结束了SparkContext的初始化。然后继续执行我们提交的应用程序代码。
应用程序执行过程:
- 根据action划分job,每执行到一个action算子就创建一个job,提交给上面的DAGScheduler, 而DAGScheduler则是通过宽窄依赖把每个job划分为多个stage,
然后每个stage创建一个TaskSet,把TaskSet提交给TaskScheduler。TaskScheduler把TaskSet里面的每个Task传给executor去执行(task分配算法)。 - executor把task包装成TaskRunner然后从线程池中拿一条线程去执行这个task,执行过程是把算子、函数进行拷贝、反序列化、执行。TaskRunner分为两类: ShuffleMapTask和ResultTask(只有最后一个stage是ResultTask)
最后spark程序的执行就是分批次的执行这些task,每个task一一对应RDD的一个partition。如此往复,所有的task都执行完成那么这个spark程序也就执行完成了。
6)Spark为什么快,Spark SQL一定比Hive SQL快吗?
Spark SQL比Hive SQL快是有前提的,其实Hive SQL的引擎是比Spark SQL的引擎快的,之所以Spark SQL快,关键还是在于Spark快。原因有以下几点:
- Spark在shuffle后数据不一定落盘,可以cache到内存中,而hadoop每次shuffle后的数据是需要写到磁盘上,这点Spark就比Hive在磁盘IO上要优越。
- Spark是基于丰富的算子操作,而hadoop每次计算都需要完整的MapReduce阶段,冗余繁琐。
- Spark每次操作都是基于executor内部线程的,只有第一次启动executor时才启动一次jvm进程,然后执行task都死线程复用的。而hadoop是每次MapReduce 都需要启动一个jvm进程。多个task执行在启动jvm进程方面就慢了好多。
7)Spark Streaming反压机制
Spark通过配置参数spark.streaming.backpressure.enabled=true(默认false)打开背压机制
背压机制组件:
- driver内部两个:RateController(速度控制器)、RateEstimator(速度评估器2.2之前版本只支持PIDRateEstimator)
- executor内部一个:RateLimiter(速度限定器)这个是抽象类目前用第三方guava的GuavaRateLimiter
8)Spark内存模型
参考: Spark内存机制
Spark中Executor是运行在工作节点的计算单元,每一个Executor都会运行一个独立的jvm,它其中就包含了计算资源(CPU和内存)
Executor内存的整体布局是分为堆内内存和**堆外内存*###
堆外内存:存储Spark内部数据和缓存,为了减少堆内存压力提高性能,不受java堆大小限制
堆内内存:JVM分配的堆内存(-Xmx),用于Executor内部的存储和计算
Spark1.6之后采用统一内存管理,它是一种规划式的管理机制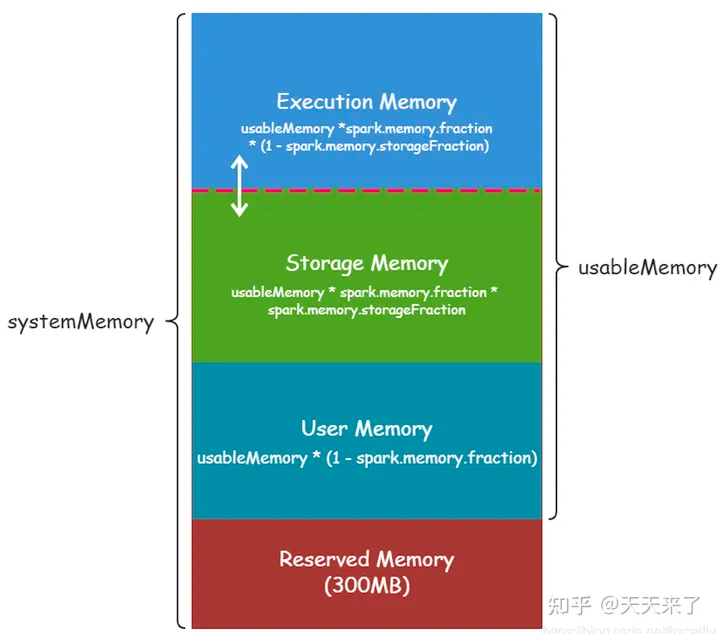
执行内存 (Execution Memory): 主要用于存放: Shuffle、Join、Sort、Aggregation 等计算过程中的临时数据
存储内存 (Storage Memory): 主要用于存储 spark 的 cache 数据,例如:RDD的缓存、unroll数据, 其中sql场景cache table等
用户内存(User Memory: 主要用于存储 RDD 转换操作所需要的数据,例如: RDD 依赖等信息
预留内存(Reserved Memory: 系统预留内存,会用来存储Spark内部对象
9)RDD、Dataset、Dataframe的区别是什么
RDD 分布式数据集
Dataset RDD通过反射、构建schema构成的
Dataframe 就是Dataset<Row>
10)Spark作业提交工作的具体流程
11)Spark容错
checkpoint机制 lineage机制
12)Spark Streaming工作流程和Storm、Flink这类流的区别
微批
13)Spark提供的两种共享变量
Spark为此提供了两种共享变量,一种是Broadcast Variable(广播变量),另一种是Accumulator(累加变量)。 Broadcast Variable会将使用到的变量,仅仅为每个节点拷贝一份,更大的用处是优化性能,减少网络传输以及内存消耗。 Accumulator则可以让多个task共同操作一份变量,主要可以进行累加操作。
广播变量 广播变量允许我们将一个只读的变量缓存在每台机器上,而不用在任务之间传递变量。广播变量可被用于有效地给每个节点一个大输入数据集的副本。 广播的数据被集群不同节点共享,且默认存储在内存中,读取速度比较快。 Spark还尝试使用高效地广播算法来分发变量,进而减少通信的开销。 Spark的动作通过一系列的步骤执行,这些步骤由分布式的shuffle操作分开。Spark自动地广播每个步骤每个任务需要的通用数据。 这些广播数据被序列化地缓存,在运行任务之前被反序列化出来。这意味着当我们需要在多个阶段的任务之间使用相同的数据, 或者以反序列化形式缓存数据是十分重要的时候,显式地创建广播变量才有用。
累加器 累加器是仅仅被相关操作累加的变量,因此可以在并行中被有效地支持。它可以被用来实现计数器和总和。Spark原生地只支持数字类型的累加器。 我们可以自己添加新类型。 提供了将工作节点中的值聚合到驱动器程序中的简单语法。
14)checkpoint的意义
15)Spark预写日志功能
WriteAheadLogs,通常被用于数据库和文件系统中,保证数据操作的持久性。预写日志通常是先将操作写入到一个持久可靠的日志文件中, 然后才对数据施加该操作,当加入施加该操作中出现异常,可以通过读取日志文件并重新施加该操作,从而恢复系统。 它引入基于容错机制的文件系统的WAL机制,若启用该机制,receiver接收到的所有数据都会被写入配置的checkpoint目录中的预写日志 这种机制可以让driver在恢复的时候,避免数据丢失,并且可以确保整个实时计算过程中,零数据丢失。
16)Spark Streaming小文件问题
参考: SparkStreaming如何解决小文件问题
(1)增加batch大小 这种方法很容易理解,batch越大,从外部接收的event就越多,内存积累的数据****也就越多,那么输出的文件数也就回变少
(2)Coalesce大法 文章开头讲了,小文件的基数是:batch_number*partition_number,而第一种方法是减少batch_number,那么这种方法就是减少partition_number了,这个api不细说,就是减少初始的分区个数。看过spark源码的童鞋都知道,对于窄依赖,一个子RDD的partition规则继承父RDD,对于宽依赖(就是那些个叉叉叉ByKey操作),如果没有特殊指定分区个数,也继承自父rdd。那么初始的SourceDstream是几个partiion,最终的输出就是几个partition。所以Coalesce大法的好处就是,可以在最终要输出的时候,来减少一把partition个数。但是这个方法的缺点也很明显,本来是32个线程在写256M数据,现在可能变成了4个线程在写256M数据,而没有写完成这256M数据,这个batch是不算做结束的。那么一个batch的处理时延必定增长,batch挤压会逐渐增大。这种方法也要慎用,切鸡切鸡啊!
(3)SparkStreaming外部来处理 我们既然把数据输出到hdfs,那么说明肯定是要用hive或者sparksql这样的“sql on hadoop”系统类进一步进行数据分析,而这些表一般都是按照半小时或者一小时、一天,这样来分区的(注意不要和sparkStreaming的分区混淆,这里的分区,是用来做分区裁剪优化的),那么我们可以考虑在SparkStreaming外再启动定时的批处理任务来合并SparkStreaming产生的小文件。这种方法不是很直接,但是却比较有用,“性价比”较高,唯一要注意的是,批处理的合并任务在时间切割上要把握好,搞不好就可能回去合并一个还在写入的SparkStreaming小文件。
(4)自己调用foreach去append SparkStreaming提供的foreach这个outout类api,可以让我们自定义输出计算结果的方法。那么我们其实也可以利用这个特性,那就是每个batch在要写文件时,并不是去生成一个新的文件流,而是把之前的文件打开。考虑这种方法的可行性,首先,HDFS上的文件不支持修改,但是很多都支持追加,那么每个batch的每个partition就对应一个输出文件,每次都去追加这个partition对应的输出文件,这样也可以实现减少文件数量的目的。这种方法要注意的就是不能无限制的追加,当判断一个文件已经达到某一个阈值时,就要产生一个新的文件进行追加了。