ClickHouse
ClickHouse是什么
ClickHouse是用于OLAP的列式存储的数据库管理系统
clickhouse有哪些特点
- 数据压缩
- 多核并行处理
- 列式存储
- 向量引擎
- 磁盘存储
- 支持较完整的ANSI SQL标准
列式存储的优点
下图更直观详细地解释原因:行式: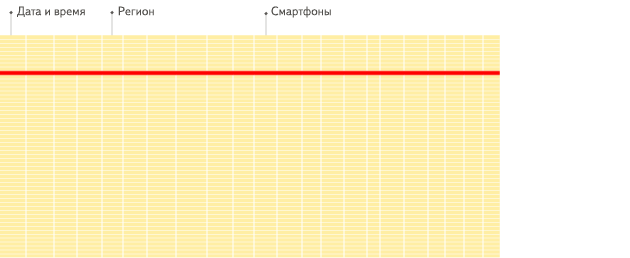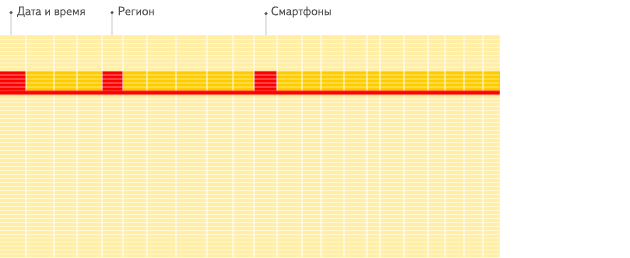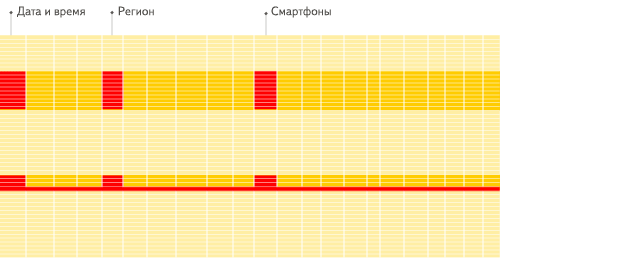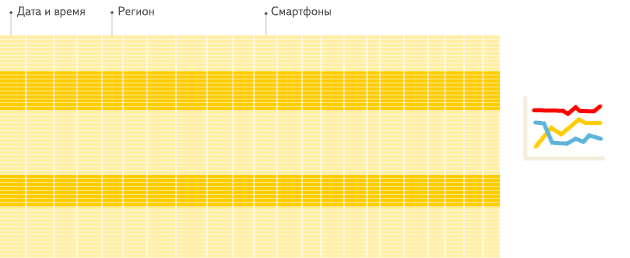
列式:
输入输出
主要是磁盘IO和体积的因素,行式的查询分析需要扫描行中所有字段数据,列式的查询直接扫描查询列,这样就减少了磁盘IO, 并且列式存储更适合数据的压缩减少数据容量。
CPU处理
一般的查询需要处理很多行,因此在每个向量上处理会比在每一行上处理要划算。
数据库引擎
数据库引擎是让你处理对应的数据,什么意思?也就是什么样的数据库引擎就可以让你通过ClickHouse处理什么样的数据库,比如MySQL数据库引擎就可以把MySQL的数据库表映射到ClickHouse,然后通过ClickHouse的操作转化成MySQL的操作发往MySQL执行、 返回结果。
Atomic (默认的数据库引擎)
支持非阻塞的DROP TABLE和RENAME TABLE查询和原子的EXCHANGE TABLES t1 AND t2查询。 在DROP TABLE上,不删除任何数据,数据库Atomic只是通过将元数据移动到/clickhouse_path/metadata_dropped/将表标记为已删除,并通知后台线程。最终表数据删除前的延迟由database_atomic_delay_before_drop_table_sec设置指定。RENAME TABLE不是原子的,EXCHANGE TABLES t1 AND t2是原子的。
RENAME TABLE new_table TO tmp, old_table TO new_table, tmp TO old_table;
EXCHANGE TABLES new_table AND old_table;
MySQL
将MySQL数据库的表映射到ClickHouse中,允许对表进行INSERT、SELECT、SHOW TABLES、SHOW CREATE TABLE操作,不允许RENAME、CREATE TABLE、ALTER操作
CREATE DATABASE [IF NOT EXISTS] db_name [ON CLUSTER cluster]
ENGINE = MySQL('host:port', ['database' | database], 'user', 'password')
PostgreSQL
将PostgreSQL数据库表映射到ClickHouse中,允许对表进行ALTER TABLE ... ADD|DROP COLUMN、SHOW TABLES、DESCRIBE TABLE操作。如果use_table_cache设置为1,则会缓存表结构,不会检查是否被修改,这时可以用DETACH、ATTACH查询更新
CREATE DATABASE [IF NOT EXISTS] db_name [ON CLUSTER cluster]
ENGINE = PostgreSQL('host:port', 'database', 'user', 'password' [, `use_table_cache`])
SQLite
Lazy
还有三种实验性的引擎
- MaterializedMySQL
- MaterializedPostgreSQL
- Replicated
表引擎
表引擎(即表的类型)它决定了:
MergeTree 合并树家族
这些表引擎最主要的一个特点就是后台会把数据按一定规则合并。
为什么会要合并?因为数据库中对现有数据的更新成本是高昂的,需要先定位到数据然后再修改那个数据。所以ClickHouse为了不使用显式的更新数据操作,采用插入新数据的方式,然后利用合并树家族的数据表引擎让所有相同主键的数据进行自动合并。
MergeTree (父类)
ClickHouse最强大的表引擎就是MergeTree引擎了,大多数*MergeTree引擎都继承自它。
CollapsingMergeTree
数据块合并算法: 折叠行逻辑折叠有两方面因素:数据和算法。换成一句话就是当满足什么样的数据时,进行什么样的合并折叠。 数据:sign字段(1 state、-1 cancel)算法:每组具有相同主键的连续行被减少到不超过两行,一行Sign = 1(<<状态>>行),另一行Sign = -1(<<取消>>行),换句话说数据项被折叠了。折叠不应该改变统计数据的结果。变化逐渐地被折叠,因此最终几乎每个对象都只剩下了最后的状态。
ClickHouse用多线程处理SELECT请求,所以不能保证结果行的顺序。要想获得准确的数据需要聚合。例如:
- 计算数量不是
count()而应该是sum(Sign). - 计算总和不是
sum(x)而是sum(Sign * x), 并且加上HAVING sum(Sign) > 0这项保证数据当前数据是状态行,而不是取消的数据 - 存在一个未被折叠的状态,聚合体
count、sum、avg可以使用上面方式计算。但是min、max这种却无法计算,因为CollapsingMergeTree不保存折叠数据的历史记录。如果需要不聚合的情况下获取数据,可以在FROM从句中使用FINAL修饰符。当然这种方法很低效。
VersionedCollapsingMergeTree
数据块合并算法: 也是折叠行逻辑,与上表引擎区别它支持快速写入不断变化的对象状态,删除后台中旧对象状态,从而显著降低了存储体积。其实就是由于增加了version字段,当折叠后的一对sign(1 state、-1 cancel)行出现version版本号相同就可以直接物理删除了。不然只是逻辑折叠。
AggregatingMergeTree
数据块合并算法: 将主键相同的数据聚合成一行数据,可以用作增量数据的聚合统计,包括物化视图的数据聚合。
# 建表
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster]
(
column1 [typeX] [DEFAULT|MATERIALIZED|ALIAS a1],
column2 [typeX] [DEFAULT|MATERIALIZED|ALIAS a2],
...
) ENGINE = AggregatingMergeTree()
[PARTITION BY columnX]
[ORDER BY columnX]
[SAMPLE BY columnX]
[TTL xxx]
[SETTINGS attribute1=value ...]
# 物化视图
CREATE MATERIALIZED VIEW test.basic
ENGINE = AggregatingMergeTree()
PARTITION BY toYYYYMM(StartDate)
ORDER BY (CounterID, StartDate)
AS SELECT
CounterID,
StartDate,
sumState(Sign) AS Visits,
uniqState(UserID) AS Users
FROM test.visits
GROUP BY CounterID, StartDate;
当数据插入到表test.visits中,数据也会同时插入到视图test.basic,并且视图会把数据进行聚合。
SummingMergeTree
ReplacingMergeTree
GraphiteMergeTree
数据副本
- ReplicatedMergeTree
- ReplicatedCollapsingMergeTree
- ReplicatedVersionedCollapsingMergeTree
- ReplicatedAggregatingMergerTree
- ReplicatedSummingMergeTree
- ReplicatedReplacingMergeTree
- ReplicatedGraphiteMergeTree
日志引擎系列
为了写入许多小数据量(少于一百万行)的表场景而开发的。 日志引擎的共同属性:
- 数据都存在磁盘上
- 数据都是追加在文件末尾
- 不支持索引 (SELECT范围或者点查询效率不高)
- 不支持突变操作
- 非原子地写入数据
StripeLog
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster]
(
column1 [typeX] [DEFAULT|MATERIALIZED|ALIAS a1],
column2 [typeX] [DEFAULT|MATERIALIZED|ALIAS a2],
...
) ENGINE = StripeLog()
Log
TinyLog
集成的表引擎
这个和上面提到过的数据库引擎类似,它是提供了与外部系统集成的功能。
- ODBC
- JDBC
- MySQL
- MongoDB
- HDFS
- S3
- Kafka
- EmbeddedRocksDB
- RabbitMQ
- PostgreSQL
- SQLite
- Hive
special (特殊的引擎)
分布式引擎
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster]
(
name1 [type1] [DEFAULT|METERIALIZED|ALIAS expr1],
name2 [type2] [DEFAULT|METERIALIZED|ALIAS expr2],
...
) ENGINE = Distributed(cluster, database, table[, sharding_key[, policy_name]])
[SETTINGS name=value, ...]
关联表引擎
Memory (内存表)
随机数生成
缓冲区
字典
用于查询处理的外部数据
文件 (输入格式)
MaterializedView
合并
Null
集合
URL (URL 格式)
视图
为什么会有这么多引擎?
ClickHouse有很多数据库引擎、表引擎,为什么需要这么多引擎? 读完上述的这些引擎,特别是表引擎,我们发现这些引擎的作用就是区分数据结构,数据位置、使用场景(查询方式、并发方式、选择索引)这和表引擎决定了什么(表的类型)呼应了。那么为什么要区分这些东西?我们发现ClickHouse有一个特点那就是向量引擎,也就是说这些引擎的划分是为了数据处理时向量化。
数据类型
我们从数据库引擎MySQL和PostgreSQL所支持的数据类型看
| MySQL | PostgreSQL | ClickHouse |
|---|---|---|
| UNSIGNED TINYINT | UInt8 | |
| TINYINT | Int8 | |
| UNSIGNED SMALLINT | UInt16 | |
| SMALLINT | SMALLINT | Int16 |
| UNSIGNED INT, UNSIGNED MEDIUMINT | SERIAL | UInt32 |
| INT, MEDIUMINT | INTEGER | Int32 |
| UNSIGNED BIGINT | BIGSERIAL | UInt64 |
| BIGINT | BIGINT | Int64 |
| FLOAT | REAL | Float32 |
| DOUBLE | DOUBLE | Float64 |
| DATE | DATE | Date |
| DATETIME, TIMESTAMP | TIMESTAMP | DateTime |
| BINARY | FixedString | |
| DECIMAL, NUMERIC | Decimal | |
| 其他 | TEXT, CHAR | String |
| ARRAY | Array |
优化查询性能
跳数索引
跳过保证没有匹配值的数据块的这种索引叫做跳数索引。 用户只能在MergeTree表引擎中才能用跳数索。跳数索引包含四个参数:
- 索引名称
- 索引表达式
- 类型
- GRANULARITY 颗粒度
主键稀疏索引
简单的讲就是并没有像B+树那样为每一行设置一个索引,而是通过颗粒度(Granule)给多行分组,然后为每一组构建一个索引。
之所以可以这么搞,因为ClickHouse是按照主键列的顺序将一组行数据存在磁盘上。那么这种稀疏索引就可以通过二分查找快速匹配行组。找到匹配行组后就把数据并行地加载到ClickHouse引擎中,以便找到匹配行。
查看执行计划
查看执行计划分析性能瓶颈
EXPLAIN SELECT ...
SELECT时可优化点
- 利用窗口函数代替子查询或者临时表、利用物化视图代替窗口函数
- 基于某一张表大量聚合处理时可以创建物化视图