HBase
数据模型
概念视图 vs 物理视图
根据 BigTable 论文修改的例子,一个名为 webtable 的表,含有两个列族 contents 和 anchor. 然后 anchor 有两个列(anchor:cssnsi.com,anchor:my.look.ca),contents 仅有一列(contents:html)
一个列名由它的 和 连接而成。例如列 content:html 是列族 contents 加冒号(:)加修饰符html组成。 概念视图
| Row Key | Time Stamp | ColumnFamily contents | ColumnFamily anchor |
|---|---|---|---|
| "com.cnn.www" | t9 | anchor:cnnsi.com = "CNN" | |
| "com.cnn.www" | t8 | anchor:my.look.ca = "CNN.com" | |
| "com.cnn.www" | t6 | contents:html = "<html >..." | |
| "com.cnn.www" | t5 | contents:html = "<html >..." | |
| "com.cnn.www" | t3 | contents:html = "<html >..." |
物理视图
| Row Key | Time Stamp | Column Family anchor |
|---|---|---|
| "com.cnn.www" | t9 | anchor:cnnsi.com = "CNN" |
| "com.cnn.www" | t8 | anchor:my.look.ca = "CNN.com" |
| Row Key | Time Stamp | ColumnFamily "contents:" |
|---|---|---|
| "com.cnn.www" | t6 | contents:html = "<html >..." |
| "com.cnn.www" | t5 | contents:html = "<html >..." |
| "com.cnn.www" | t3 | contents:html = "<html >..." |
行键(RowKey)设计
单调递增行键、时序数据
单调递增或者时序的行键不是好的选择,因为新加入的数据会集中在一个 region 上,这就导致了热点问题,而且固定一个 region 一直膨胀就会 split。
- 给单调或者时序的行键前面加上一个随机前缀,类似于:[metric_type][event_timestamp]
- 时序行键可以反转 、 单调行键可以加上一个反转时序的后缀.
尽量最小化行和列的大小
真是存储的值是在一个 Cell 中的,要是定位这个 Cell 用的坐标很大,也就是这个行键和列名比较大的时候,会占用很多的内存,以至于索引(内存)会被用尽。所以在设计的时候尽可能的减少行键和列名的大小。比如
架构
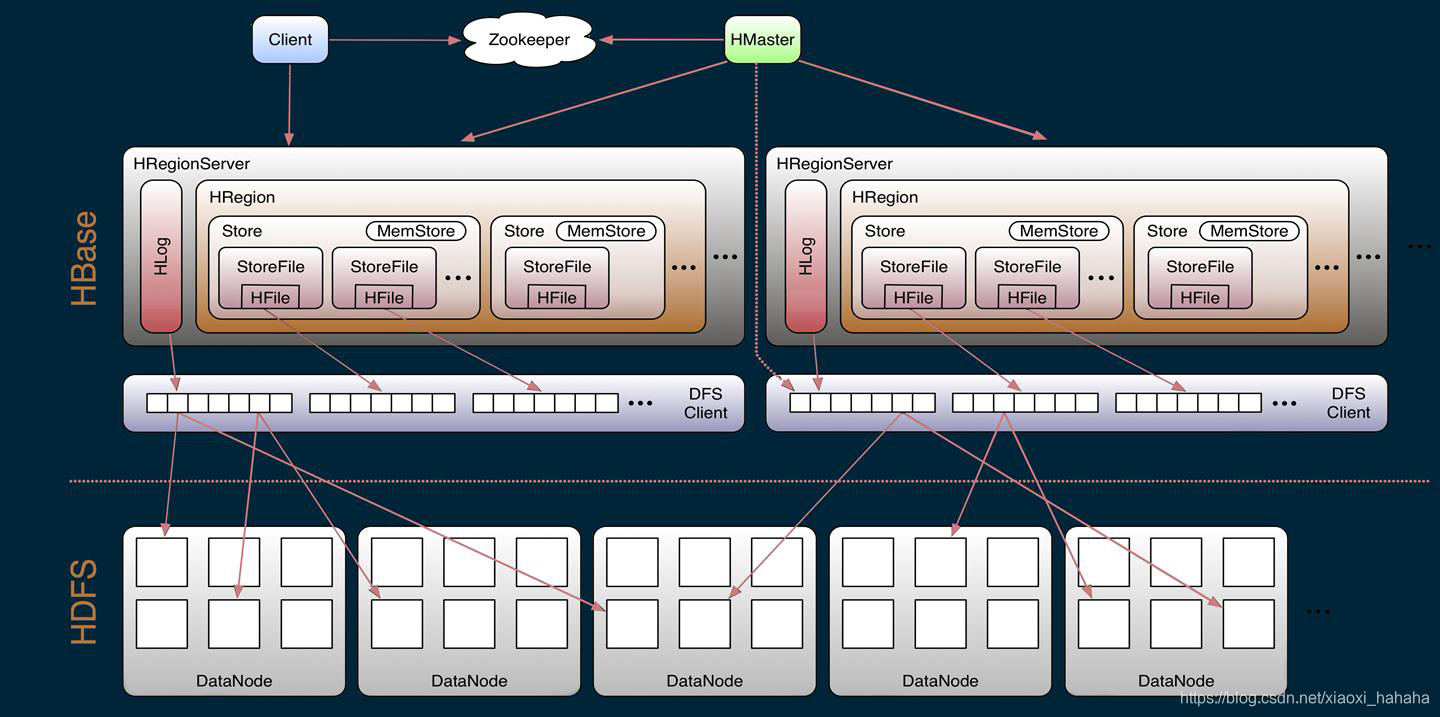
HBase 是一种NOSQL、列式存储、大型分布式、强一致性读写、自动分片Audomatic sharding的数据库。
HBase 不适合所有问题。
首先,确信有足够多的数据,如果有上亿或者上千亿行数据,HBase 是很好的选择。
其次,不依赖关系型数据库的特性(比如 二级索引、事务、高级查询)。
第三,需要确保有足够的硬件,比如 HDFS 在小于5个数据节点时,干不好什么事情(HDFS块复制缺省值3)还要加上一个 NameNode。
除了上述的一些特征,我们要知道 HBase 的一些优缺点,比如它的高速读写、随机查询性能高,但是不适合范围扫描,不适合做数据分析 OLAP 等。
目录表(Catalog Tables)
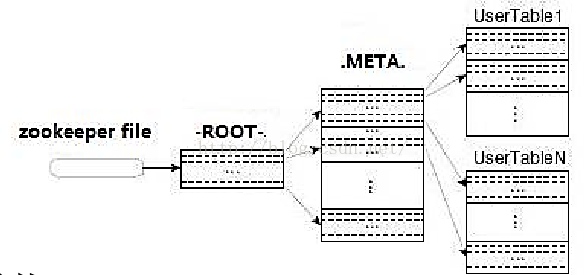
所谓的目录表,就是指 HBase 的三级寻址,0.96之后变成了二级寻址。目录表 -ROOT- 和 .META 也是HBase的表,但是它们被 HBase Shell 的 list 命令所过滤了,除此和其他表一样的存在。
Key:
- .META. region key (.META.,,1)
Values:
- info:regioninfo (序列化.META.的 HRegionInfo 实例)
- info:server (保存 .META. 的 RegionServer 的 server:port)
- info:serverstartcode(保存 .META. 的 RegionServer 进程启动时间)
Key:
- Region Key 格式([table],[region start key],[region id])
Values:
- info:regioninfo (序列化 .META. 的 HRegionInfo 实例)
- info:server (保存 .META. 的 RegionServer 的 server:port)
- info:serverstartcode (保存 .META. 的 RegionServer 进程启动时间)
客户端
负责寻找相应的 RegionServers 来处理行。他先查询 .META. 表,确定了 region 的位置后,客户端会直接访问 region(不经过 master)发起读写请求。这些信息会缓存在客户端,这样就不用每次请求都去查询 .META. 表。如果一个 region 已经废弃(原因可能是 master load balance 或者 RegionServer 挂了),客户端才会重新查询 .META. 表获取新的 region 地址。客户端请求过滤器
HBase 的 Get、Scan 操作可以使用配置,应用于 RegionServer.
- 结构过滤器(Structural)结构过滤器包含其他过滤器
FilterList - 列值过滤器(Column Value)用于过滤列值相等的过滤器
SingleColumnValueFilter、ColumnValueFilter - 列值比较器(Column Value Comparators)用于过滤列值比较的过滤器
RegexStringComparator、SubstringComparator、BinaryPrefixComparator、BinaryComparator、BinaryComponentComparator - 键值元数据(KeyValue Metadata)评估一行的键是否存在(如: ColumnFamily:Column qualifiers)
FamilyFilter、QualifierFilter、ColumnPrefixFilter、MultipleColumnPrefixFilter、ColumnRangeFilter - RowKey(RowKey)通常认为行选择 Scan 采用 startRow/stopRow 方法比较好,也可以用
RowFilter - Utility(Utility)这主要用于行计数作业
FirstKeyOnlyFilter
Master
HMaster/Master Server 主要负责监控所有的 RegionServer 实例。暴露元数据更改的接口,
HMasterInterface 暴露的方法主要是面向 的方法:
- Table (createTable, modifyTable, removeTable, enable, disable)
- ColumnFamily (addColumn, modifyColumn, removeColumn)
- Region (move, assign, unassign) 比如说,当 调用
disableTable方法时,它就会发送 rpc 到 HMaster,然后由 HMaster 实现。
- LoadBalancer 定期地将没有处于过渡中(transition)的 regions,负载均衡到集群的各个节点上。
- CatalogJanitor 定期地检查和清理 hbase:meta/.META. 表
RegionServer
HRegionServer/RegionServer 负责管理 regions,
HRegionRegionInterface 暴露的方法主要是面向 和 的:
- Data (get, put, delete, next, etc.)
- Region (splitRegion, compactRegion, etc.) 比如说,当 对于 Table 调用
majorCompact方法时,客户端实际上是遍历指定表所有的 regions,并直接 rpc 请求每个 region 所在的 RegionServer 对 Table 执行 major compact 操作。
- CompactSplitThread 检查分裂并处理 minor compact
- MajorCompactionChecker 检查 major compact
- MemStoreFlusher 周期性的将内存存储刷新到文件存储
- LogRoller 周期性的检查 RegionServer 的预写日志 WAL/HLog
协处理器(CoProcessors)
在0.92版本中添加了协处理器,具体可以参考hbase的协处理器
- observer 类似于 RDBMS 中的触发器,主要在服务端工作
- endpoint 类似于 RDBMS 中的存储过程,主要在服务端工作
缓存块(Block Cache)
HBase 提供两种不同实现的缓存块,从 HDFS 中读取数据缓存到本地。一种是默认的基于堆的 ,另一种非堆的
LruBlockCache 上的,如果打开了 BucketCache 那么就要管理两层缓存系统L1(LruBlockCache)、L2(BucketCache),这样它是由一个叫做 CombinedBlockCache 来实现的。预写日志 WAL/HLog
预写日志的目的是为了数据的。每个 RegionServer 会将更新(Puts、Deletes)先记录在预写日志中(WAL),然后更新到 Store 的 MemStore 上,最后再由MemStoreFlusher输入到文件系统持久化。如果没有预写日志,当 RegionServer 挂了还没有刷到文件系统时,那这份数据就丢失了。HLog 是 HBase 的一个 WAL 实现,
Regions(分区)
Region 逻辑上存的是表中连续行的数据,物理上存的是各个列族库(Store)。Store 包含了一个内存存储(MemStore)和若干个文件存储(StoreFile--HFile),一个 Store 就是一个列族(ColumnFamily)的 region
Table (HBase table)
Region (Regions for the table)
Store (Store per ColumnFamily for each Region for the table)
MemStore (MemStore for each Store for each Region for the table)
StoreFile (StoreFiles for each Store for each Region for the table)
Block (Blocks within a StoreFile within a Store for each Region for the table)
Region 的大小是一个棘手的问题,需要考虑的因素很多。分布式的基本单位、太多性能下降、太少分布不均匀、压力集中、1个region还是10个region的索引需要内存差别不大
Region的启动、故障转移、负载均衡、状态 Transition
启动:调AssignmentManager > 在.META.中找到region地址 > region 分配有效继续 > region 分配无效调用LoadBalacerFactory重新分配 region,其中DefaultLoadBalancer 将随机分配区域到RegionServer. > 更新 .META. RegionServer 启动这个 region 的开启代码
故障转移:RegionServer 故障时,region 获取不到 > Master 检测到 RegionServer 退出 > region 分配无效,后续和启动类同
负载均衡:参考上面 Master 中的后台线程 LoadBalancer,周期性地把没有处于过渡中的 regions,负载均衡到集群的各个节点上
状态 Transition:每个 region 的状态信息都维护在 hbase:meta 中,而这个表的 region 状态持久化在 ZooKeeper 上。状态包含了好多种,以及状态转换图,参考 Region State Transition
Region 和 RegionServer 本地化
一次刷新或者compact后,就可以做到数据的本地化。
- 第一个副本写在本地
- 第二个副本写到不同机架的随机节点
- 第三个副本写到与第二副本同机架的不同节点
- 后续副本写到集群的随机节点上
split
RegionServer 的 ,因为 。还可以
RegionServer split region 的步骤是:region 下线 > split > 将它的子 region 加入到 .META. 表中 > 上线新 region > 汇报给 Matser
批量加载(Bulk Loading)
HBase 有好几种方式加载数据到表。最直接的就是通过 MapReduce 任务、Client API。批量加载是通过 MapReduce 任务,将表输出为 HBase 内部数据格式,然后把数据加载到 HBase 集群的数据目录中。这是比较高效的方式。
HDFS
HBase 底层的存储就是 HDFS,所以理解 HDFS 结构就能很好的理解它如何存储文件和做故障转移。理解 HDFS: NameNode 负责维护文件系统的元数据。DataNode 负责存储 HDFS 的存储。
ZooKeeper
一个分布式运行的 HBase 都要依赖 ZooKeeper 集群。每个 HBase 的客户端或者是节点都要和 ZK 访问。默认情况下 HBase 集群是自包含一个 ZK 集群的,当然也可以使用外部的 ZK 集群,这需要额外的去配置: 首先关闭内部开关 conf/hbase-env.sh 里面的 HBASE_MANAGES_ZK 默认是 true,设置false关闭。其次配置 ZK 集群,通过修改 CLASSPATH 下的 zoo.cfg 或者更简单的方法是修改 hbase-site.xml 中的 zookeeper 配置。